PowerDB - OLAP
Online analytical processing (OLAP) aims at analyzing vast amounts of data in order to prepare strategic decisions. Modern OLAP systems must cope with very large volumes of data and at the same time must allow for short response times to facilitate interactive usage. Another requirement, which is getting more and more important, is that the data analyzed should be up-to-date.
We aim at these requirements using a cluster of databases as basic infrastructure. Our approach features a distinguished coordinator that 'manages' the entire cluster: The coordinator decides what to store at each cluster node. It is responsible for scheduling and routing of client requests within the cluster. Such a cluster is becoming a cost-effective alternative to more expensive commercial supercomputers. It gives us parallelism and provides "scale-out" characteristics. By deploying commercial off-the-shelf components (COTS) we are also in line with the general research theme of our group, i.e., building large systems from standard hardware and software components.
We concentrate on full replication as physical data organization scheme. This gives us inter-query parallelism and fault tolerance. The aim of our research is the development and evaluation of sophisticated routing and scheduling strategies. So far, we have investigated query routing techniques which take the state of the component caches into account to maximize the cache hit rate. An important constraint is that the coordinator respects the principle of encapsulation when accessing its components. Consequently, it cannot look up the cache directories. Instead, it must base its routing decisions on the history of past queries only. Nevertheless, our techniques proofed very effective and better than state-of-the-art strategies by a factor of two with regard to mean response time.
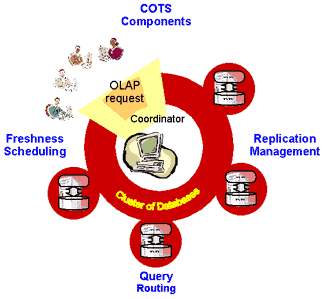
Scheduling ensures the correct interleaved execution of queries and updates, and that updates go to all replicas. We investigate scheduling strategies, which allow to deal query-result accuracy for performance. We refer to these strategies as freshness-aware scheduling. The idea is that update propagation can be interleaved with query processing more efficiently in the presence of queries that agree to be evaluated on stale data: Queries are only evaluated on cluster nodes whose fresh-ness meets the minimal degree of freshness specified by the query. Refresh transactions propagate updates to replicas using a lazy replication approach. Preliminary experiments show that this results in a much higher degree of scalability and only a minimal slowdown of queries and updates.
We have developed a full-fledged cluster of databases prototype. It features a freshness-aware scheduler and a cache-approximation query router, and can process arbitrary SQL92-compliant query and update transactions. This allows the use of queries of realistic complexity, i.e., the TPC-R benchmark for decision support systems, for the evaluation of our algorithms.